Learning Enriched Features for Real Image Restoration and Enhancement 이해하기
18 Mar 2021
Reading time ~5 minutes
Learning Enriched Features for Real Image Restoration and Enhancement
MIRNet이라고 이름 붙인 이 네트워크 구조는 2020년 ECCV에 소개된 논문 Learning Enriched Features for Real Image Restoration and Enhancement 에서 제안한 구조입니다.
논문의 링크와 제작자의 코드 깃허브 링크는 아래와 같습니다.
논문 주소 :https://arxiv.org/pdf/2003.06792v2.pdf
코드 깃허브 : https://github.com/swz30/MIRNet
Introduction
이 논문의 저자들은 기존의 Image Enhancement 구조인 Encoder-Decoder 구조와 high-resolution(single-scale) 구조들의 문제점을 지적합니다. 기존 네트워크의 문제점들이란, 제한된 수용영역(receptive fields)에서 맥락과 관련된 정보들(contextual information)을 뽑아내는데 제한적이라는 것입니다. 따라서 이러한 수용 영역을 늘리기 위해, 이 논문에서는 multi-scale approach를 사용합니다. 고해상도에서의 특징맵을 계층적으로 쌓고, 공간적 세부 loss들을 최소화 하는 방향으로 학습합니다. 동시에, parallel convolution streams를 구축하여, multi-resolution feature들이
교류하며 정보를 교환합니다.
이 논문에서 제시하는 방식이 기존의 방식들과 다른 점은, multi-scale로 얻어낸 맥락 특징들(contextual information)을 종합하는 방식에 있습니다. 기존의 방식들은 대체로 각 scale에서 얻어낸 정보를 독립적으로 취급하거나, top-down 방식으로만 데이터를 종합합니다. 이와는 반대로, 이 MIRNet 모델에서는 top-down, bottom-up 방식의 교류가 모두 이루어지며, 동시에 coarse-to-fine, fine-to-coarse의 교환 역시 이루어집니다. 이는 SKKF mechanism에 의해 이루어지는데,
MIRNet의 핵심이라고 할 수 있습니다. 이러한 방법의 차이는 최종적으로, 여러 scale에서 얻어낸 feature들을 기존의 방식처럼 단순하게 더하거나, 평균을 내거나 합치는(concatenation) 방식이 아니라 feature들을 동적으로 선택하기 때문에, 더 좋은 결과를 얻어낼 수 있습니다.
Proposed Method
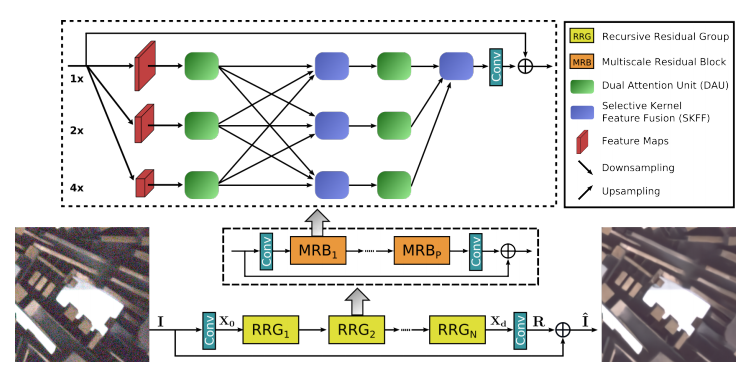
1. RRG(Recursive Residual Group)
RRG는 Recursive Residual Group의 약자로, 연속되는 MRB 구조를 포함하고 있습니다. MRB 구조의 재귀로 성능 향상을 위해 사용됩니다. 논문에서는 2개의 RRG를 사용하는 것을 제안하고 있습니다
2. MRB(Multiscale Residual Block)
MIRNet 구조의 핵심이라고 할 수 있는 Block입니다. 하나의 RRG 안에 여러개의 MRB가 포함되어 있는 구조이며, 논문에서는 하나의 RRG에 3개의 MRB를 넣어 예시로 사용하였습니다. MRB는 다양한 크기의 공간 정보를 효과적으로 다루기 위해 원본 크기의 high-resolution representations 외에도 low-resolution에서도 feature들을 뽑아내어 풍부한 contextual information을 얻어냅니다. MRB는 여러개의 fully-convolutional stream들이 평행으로 이어져 있으며, 이는 각 stream들의 low-resolution feature와 high-resolution feature 간의 정보 교환을 가능하게 합니다.
3. SKFF(Selective Kernel Feature Fusion)
MRB의 구조를 이루고 있는 요소 중 하나인 SKFF는 multi-scale feature를 생성하고, aggregation and selection을 수행합니다. 대부분의 Image Enhancement 구조들이 feature들을 aggregation할때 단순하게 wide-sum이나 concatenation 을 통해 feature들을 합칩니다. 그러나 이러한 구조의 네트워크는 표현력에 한계를 갖습니다. MIRNet에서는 이러한 문제를 해결하기 위해 MRB의 안에서 multi-resolution의 feature들을 합치고, 선택하는 non-linear procedure를 만들었는데, 이를 SKFF라고 부릅니다.
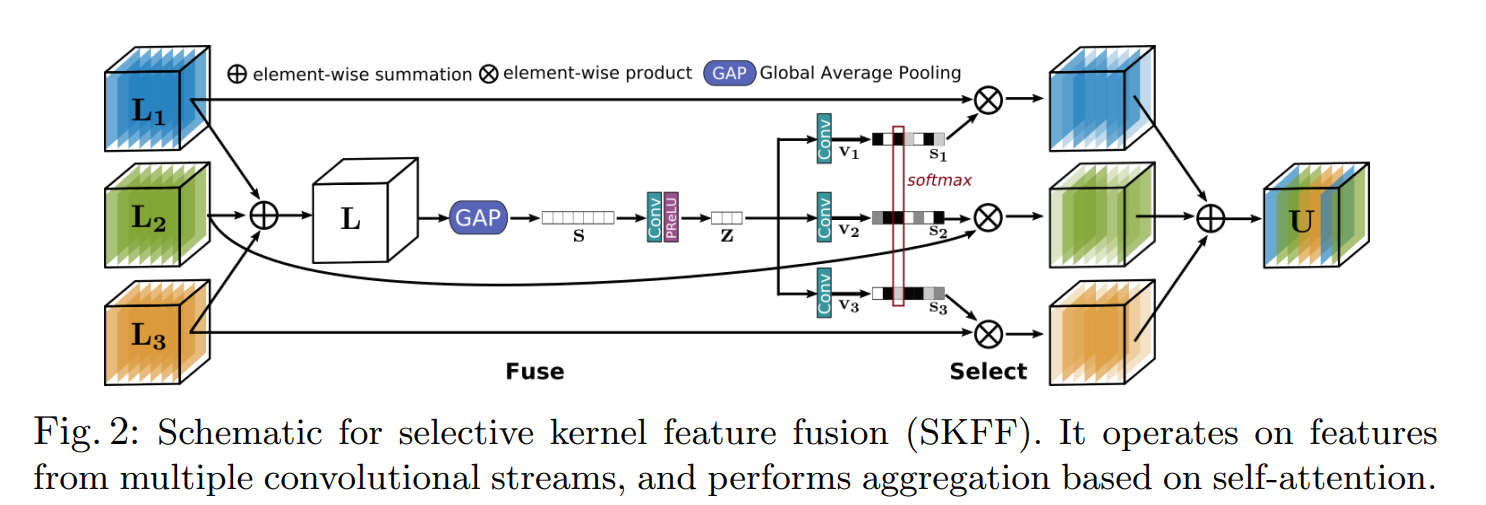
SKFF 모듈은 Fuse와 Select라는 2가지 연산을 통해 동적인 조정을 수행합니다. FIg. 2.의 fuse 연산은 multi-resolution stream들의 정보를 합치며 전역적 기술자(global descriptor)들을 생성한다. select operator는 이 기술자들을 이용하여 feature map들의 aggregation에 따른 재보정 연산을 수행합니다.
nbsp; Fuse 연산과 Select 연산의 자세한 설명은 다음과 같습니다.
- Fuse : SKFF의 입력은 3개의 다른 scale의 정보를 갖고 있는 parallel convolution streams입니다. SKFF에서는 먼저 이 3개의 multi-scale feature를 wise-sum을 통해 하나로 통합합니다. 그리고 global average pooling을 spatial dimension에 적용하여 벡터화하고, 이를 다시 channel down scaling convolution layer를 통해 작은 크기의 feature \(z\)를 생성합니다. 최종적으로, \(z\)를 3개의 평행한 channel upscalling convolution layer들을 통해 3개의 특징 기술자(feature descriptor) \(v1,v2,v3\)(1x1xC 크기의 벡터)를 얻게됩니다.
- Select : select 단계는 fuse 단계의 이후로, \(v1,v2,v3\) 3개의 벡터를 softmax function을 통해 yielding attention \(s1,s2,s3\)로 변환합니다. 이들은 multi-scale feature map들을 재조정하는데 사용됩니다.
SKFF의 전체적인 프로세스는 feature들을 재조정하고, 그 집합을 만드는 것입니다. SKFF는 단순히 concatenate 하는 것보다 적은 파라미터를 사용하면서도 조금 더 좋은 결과를 만들어냅니다.
4. DAU(Dual Attention Unit)
SKFF block은 multi-resolution branch들을 통해 information들을 융합시킵니다. 여기에 더해 spatial and channel dimension 간의 feature tensor 간의 정보를 공유할 구조가 필요합니다. MIRNet에서는 이 문제를 해결하기 위해 최근의 low-level vision 연구들을 기반으로 Dual Attention Unit, 즉 DAU라고 불리는 구조를 삽입하였습니다. DAU의 구조는 fig. 3.과 같습니다. 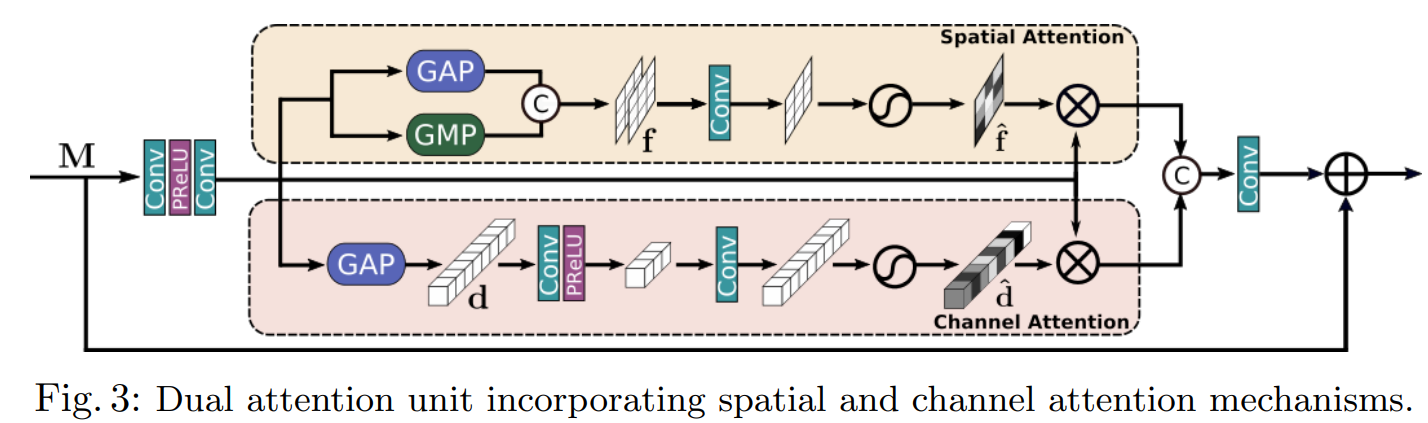
DAU 활용성이 적은 feature들의 영향을 줄이고, 정보가 많은 feature들이 더 많이 통과되도록 합니다. 이러한 feature들의 재조정은 다음에 소개할 channel attention과 spatial attention 구조에 의해 이루어집니다.
- Channel Attention(CA) : figure 1.을 보면 MRB 구조에서 DAU는 SKFF의 앞에 한 번, 뒤에 한 번 scale당 총 2번씩 사용되는 것을 확인할 수 있다. Channel Attention branch는 여기서 convolution feature map 간의 채널 간 연관성을 squeeze와 excitation 연산을 통해 짜냅니다. 주어진 feature map \(M \in {\mathbb{R}^{H\times W \times C}}\)에서 global context를 encoding 하기 위해 global average pooling 연산을 수행하고, 이 유연한 특징 기술자(feature descriptor) \(d \in {\mathbb{R}^{1 \times 1 \times C}}\)가 됩니다. 이 \(d\)는 2개의 convolution layer를 통과하고 sigmoid 활성화함수를 통해 \(\hat{d} \in {\mathbb{R}^{1 \times 1 \times C}}\)가 되고, channel attention 의 output branch는 이 \(\hat{d}\)를 \(M\) 의 크기로 resize한 것이 됩니다.
- Spatial Attention(SA) : figure 3.에 나오는 DAU의 구조 중 윗 부분이 SA 메커니즘입니다. CA가 채널 간 연관성(inter-channel relationship)을 추출한다면, SA는 convolution feature의 공간 의존성(inter-spatial dependencies)을 추출하고, 이를 feature들의 재조정에 사용합니다. SA를 생성하기 위해서 global average pooling과 global max pooling을 각각 독립적으로 적용한 후 그 결과물들으 하나로 합쳐서 feature map \(f \in {\mathbb{R}^{H \times W \times 2}}\)으로 만듭니다. 이렇게 만든 \(f\)는 convolution and sigmoid layer를 통과하여 spatial attention map \(\hat{f} \in {\mathbb{R}^{H \times W \times 1}}\)으로 만들고 \(M\)으로 다시 rescale 합니다.
5. Residual Resizing Module
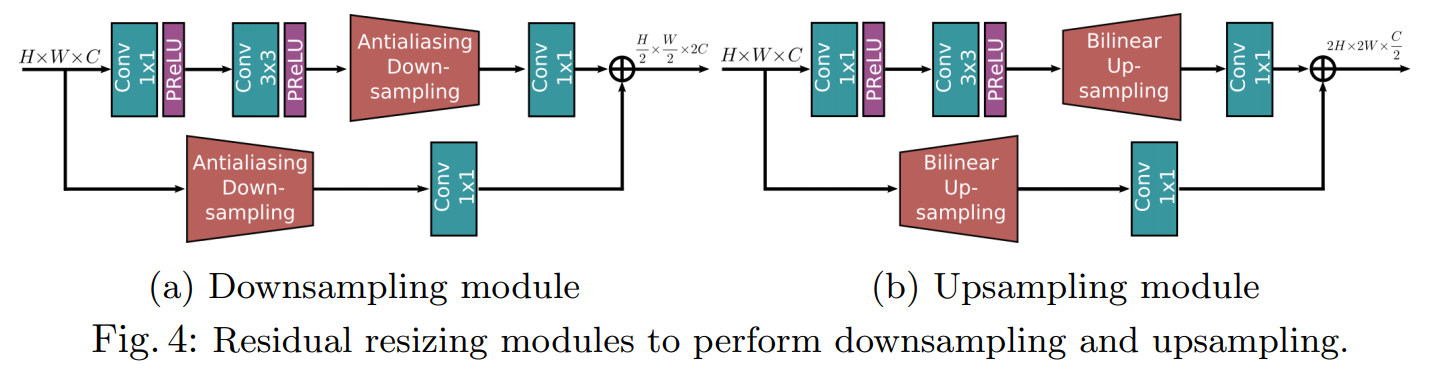
MIRNet은 skip connection이 존재하는 recursive residual design으로 되어있습니다. 구조 내에서 residual nature를 유지하기 위해서는 resize 시에도 그 특성이 보존되도록 해야합니다. Fig.4.는 MIRNet에서 사용하는 resize method인 residual resizing의 구조에 대해서 보여주고 있습니다. MRB에서 feature map의 크기는 바뀌어 3개의 stream들로 나누어집니다. 이 때 input resolution index \(i\)와 output resolution index \(j\)를 받게 되는데 만약 \(i <j\)이면 downsampling을 수행하고, 그 반대라면 upsampling을 수행합니다. \(2 \times\) downsampling을 수행하기 위해, Fig.4.(a)의 구조를 사용하였고, 만약 \(4 \times\)의 downsamping을 수행한다면 이 구조를 반복적으로 2번 적용하면 됩니다. 이와 마찬가지로 \(2 \times\) upsampling을 진행하기 위해서는 Fig.4.(b)의 구조를 한 번, \(4 \times\)의 upsampling을 필요로 하면 이 구조를 반복하여 2번 수행함으로서 원하는 결과를 얻을 수 있습니다.
Experiments
이 section 에서는 MIRNet으로 만들어진 결과들에 대한 양적인 평가와 다른 method들과의 비교들로 이루어져 있습니다. 논문에서는 image denoising, super-resolution, image enhancement에 대한 결과들이 모두 나와있는데, 여기서는 image enhancement에 관한 부분만 다루도록 하겠습니다.