Kindling the Darkness : A Practical Low-light Image Enhancer
Kindling the Darkness는 Low light image enhancement 기법을 소개하는 논문입니다. 논문 파일의 주소 및 github 주소는 아래와 같습니다.
논문 주소 : https://arxiv.org/pdf/1905.04161.pdf
코드 깃허브 : https://github.com/zhangyhuaee/KinD
Introduction
high-quality의 이미지를 빛이 부족한 상태에서 찍는 것은 굉장히 어려운 일입니다. 이러한 문제를 해결하기 위해 ISO를 증가시키거나, 노출을 증가시키는 방법이 있지만, 이러한 방법들은 image에 noise가 생기게 합니다. 따라서, low light image enhancement는 굉장히 중요한 분야입니다. 지난 수 년간 low-light image enhancer를 만들기 위한 다양한 시도들이 존재했지만, 밝기에 유연하게 대응하고, degradation을 효과적으로 제거하며, 효율적인 부분까지 모두 고려해야 하므로, 실용적인 low-light enhancer를 개발하는 것은 여전히 어려운 일입니다.

Deep learning 기반의 enhancement 기법들(SR, Denoising 등의)은 기존의 기법들에 비해 훨씬 좋은 성능을 보여주지만, 대부분은 ground truth data를 포함하는 dataset을 필요로 합니다. 실제 low-light image의 경우, 사람들이 선호하는 조도는 각자 다를 수 있기 때문에, 특정 조도에 대해서만 학습하는 것은 유용하지 않습니다. 기존 daataset을 통해 학습하는 방법들에는 이러한 문제가 있었기 때문에, KinD에서는 well-defined ground-truth 없이 2장/혹은 몇몇의 다른 샘플들을 통해서 학습하는 것을 목표로 합니다.
Previous Method
Plain Method
Plain Method란, Histogram Equalization, Gamma Correction(감마 보정) 등의 method들을 말한다. 이런 문제들은 실제 조명 요인을 고려하지 않고, 일반적으로 향상된 결과를 제공하므로, 실제 장면과 일관되지 않는 이미지가 나온다.
Traditional Illumination-based Methods
Plain method와는 다르게, 이 방법들은 조도를 고려하는 방법들이다. 이러한 방법들은 Retinex theory에 기반하여, image를 reflectance와 illumination이라는 2개의 요소로 나누어 처리한다. 하지만 이러한 방법들 역시 결과 이미지가 자연스럽지 않다거나, 지나치게 대조되는 부분이 생기는 등의 문제가 발생합니다.
Deep Learning-based Methods
딥러닝 기법의 발견 이후, 많은 딥러닝 method들이 제안되었는데, 이 방법들은 대체로 denoising, super-resolution, dehazing등의 기법이었습니다. 이 논문에서 제안하는 low-light enhancement를 딥러닝 방법으로 처음 제안한 것은 LLNet이고, 이후에도 많은 deep learning 방법들이 제안되었습니다. 기존의 방법들은 대체로 noise가 다양한 빛을 통해 각 지역에 다른 영향을 준다는 것을 고려하지 않고 만들어진 “ground-truth” 이미지를 target 삼아 학습하기 때문에, noise나 색의 왜곡이 발생하기도 합니다.
Image Denoising Methods
영상처리, 컴퓨터 비전, 멀티미디어 분야에서 오래 연구되어 온 주제 중 하나인 denosing은 과거에는 이미지의 일반화를 통해 해결하는 경우가 많았습니다. 가장 유명한 방법 중 하나인 BM3D와 WNNM은 테스트 성능은 잘 나오지만, 실제 데이터를 통해 denoising을 수행하면, 결과가 만족스럽지 않게 나옵니다. 최근에는 딥러닝 기반의 method들도 나오고 있는데, autoencoder를 사용하는 방법이나, feed-foward convolution network를 이용하는 방법들도 있습니다. 하지만, 이러한 방법들도 여전히 blind image denoising의 수행에는 어려움을 갖고 있고, 많은 파라미터를 요구하기 때문에 학습에 어려움을 겪습니다. Recurrent를 통해 이러한 문제는 어느정도 해결할 수 있지만, 이미지의 다른 영역이 다른 noise 수준을 갖는다는 것을 명시하고, 이에 대해 처리하는 네트워크는 적습니다.
Methodology
KinD 네트워크의 목표는 이미지 속에 숨겨진 degradation들을 효과적으로 제거하고, 유연하게 노출과 광량을 조절할 수 있어야 합니다. KinD에서는 이를 위해 네트워크를 reflectance와 illumination 요소를 다루는 2가지 구조로 나누고, 또한 이를 레이어 분리, reflectance 복원, 그리고 illumination 조정의 3가지 파트로 나눌 수 있습니다. 이번 섹션에서는 이러한 네트워크들의 구성과 역할에 대해 다룹니다.
Consideration & Motivation
이 파트에서는 네트워크의 각 구조의 필요성과 개발 동기에 대해 다룹니다.
Layer Decomposition
Plain method들에 대해 설명하며 문제로 꼽았던 점 중 하나가 실제 조명에 대해 고려하지 않는다는 점이었습니다. 이를 위한 해결책은 조명 정보(illumination information)에서 얻을 수 있습니다. Input으로부터 조명 정보를 잘 뽑아낸다면, degradation을 지울 수 있거나, 복원할 수 있는 detail에 대해 알 수 있습니다. Retinex theory에서는 이미지 $I$는 2가지 구성 요소의 집합이라고 할 수 있는데, reflectance $R$과 illumination $L$이 그 구성요소입니다.
Data Usage & Priors
실제 이미지에 대해여 light condition이 잘 정의된 ground-truth 이미지는 적거나, 없는 경우가 많습니다. Image에 degradation이 적용되어 있지 않다고 가정할 때, 어떤 scene의 다른 여러개의 사진들이 같은 reflectance를 공유해야 합니다. 반면에 Illumination map은 집중적으로 변화하는 구간은 있지만, 상호 연관성이 존재하는 구조입니다. 실제 상황에서는 low-light 영상의 degradation이 밝은 이미지보다 나쁜 경우가 많으며, 이는 reflectance 값에 반영되게 됩니다. 이에 따라, 밝은 이미지를 reference로 degraded low-light one을 복원하는 학습에 사용할 수 있다는 것을 알 수 있습니다. 인공적인(synthesize) data를 사용하지 않는 것은 degradation은 단순한 형태가 아니며, 다른 센서에 따라 변화하기 때문에 인공적으로 이를 재현하는 것은 어렵기 때문에 사용하지 않습니다.
Illuminatoin Guided Reflectance Restoration.
분해된 reflectance에서, 어두운 illumination 의 오염은 밝은곳에 비해 더 무겁습니다. 수학적으로, 저하된(degraded) low-light 영상은 $I=R \circ L+E$(E는 오염된 요소)로 표현할 수 있습니다. 이를 수학적으로 간단하게 풀면 다음 수식을 얻을 수 있는데
\[I=R \circ L+E= \tilde{R} \circ L = (R+ \tilde{E}) \circ L=R \circ L + \tilde{E} \circ L,\]로 표현할 수 있습니다. 여기서 $\tilde{R}$ 은 오염된 reflectance를 말하며, $\tilde{E}$는 분리된 illumination의 degradation을 의미합니다. 예를들어, White Gaussian noise $E ~ \mathcal{N}(0,\sigma^2)$를 적용한다면 $\tilde{E}$의 분포는 더 복잡해질 것이고, $L$에 더 강하게 영향을 받게 됩니다. 이는 즉, reflectance의 복원은 단순하게 일괄적으로 적용할 수 있는 것이 아니며, illumination map이 reflectance 복원에 좋은 guide 역할을 해줄 수 있다는 것을 의미합니다.(어떻게?) 그렇다면, 직접적으로 $I$에서 $\tilde{E} 를 지우는 방법을 사용하는 것에 대해 생각해볼 수도 있습니다. 한 가지 이유로, 불균등 문제가 여전히 남아있습니다. 다른 관점에서 보자면, 고유한 세부 요소들이 noise들과 혼동될 수 있습니다. reflectance 외의 점으로는, 다양한 L(illumination) degradation 제거에 있어서 적절한 reference를 가지고 있지 않기 때문에, 유사한 분석을 하게 되는데, 이는 color-distortion과 같은 다른 유형의 degradtion을 제공하게 됩니다.
Arbitrary Illumination Manipulation
사람마다 선호하는 조명 강도(illumination strength)는 다양할 수 있습니다. 그러므로, 실제 시스템은 임의의 조명 조작을 위한 인터페이스를 제공할 필요가 있습니다. 논문에서는 조명 세기를 향상시키기 위해서 3가지 방법을 주로 사용하는데 fusion, light level appointment, gamma correction 이 이에 해당됩니다. Fusion 기반의 방법들은 fixed fusion mode로 인해서 빛의 세기를 조정하는 기능이 부족합니다.(왜??) 두 번째 옵션을 채택할 경우(light level appointment를 말하는듯) 데이터 셋에는 목표 수준의 영상들이 포함되어야 하므로 학습의 유연성이 제한되게 됩니다. Gamma correction의 경우, 이는 각각 다른 $\gamma$값들을 통해서 목표에 도달할 수 잇찌만, light level과의 상관관계를 반영하는 것은 불가능합니다. 이 논문은 사용자가 임의의 빛과 노출 수준을 지정할 수 있도록 허용하는 유연한 mapping function을 실제 데이터를 통해 학습할 수 있도록 합니다.
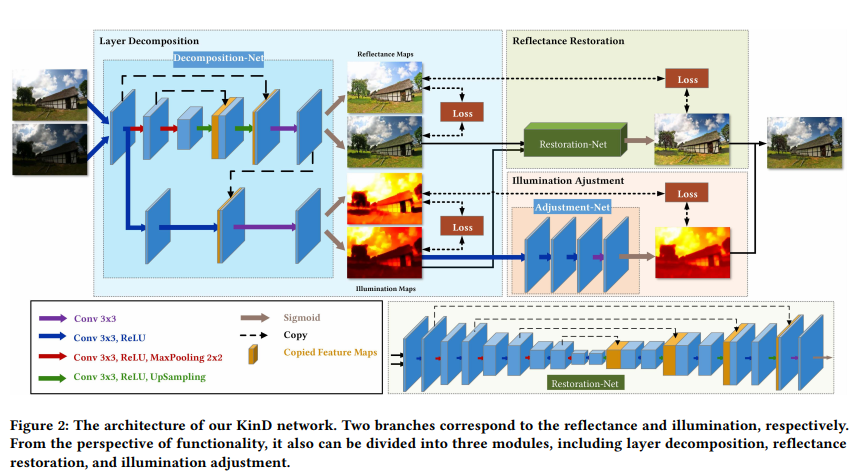
KinD Network
위에 소개한 consideration & motivation을 바탕으로, 논문의 저자들은 KinD라는, kindling the darkness deep neural network를 설계하였습니다. 이 아래에는 3개의 subnet에 대한 설명과 기능적 관점에 대한 세부사항에 대하여 묘사합니다.
Layer Decomposition Net
하나의 이미지로부터 2개의 구성요소를 복원하는 것은 설정이 잘못된 문제라고 할 수 있습니다. Ground-truth 정보가 없다면, 잘 디자인 된 제한적인 로스가 중요합니다. 따라서, KinD에서는 2개의 다른 빛 세기 / 노출 정도를 가진 이미지 $[I_l,I_h]$를 준비합니다. 특정 장면의 reflectance는 설 다른 image들에 거쳐 공유해야한다는 것을 생각하면, 분해한 reflectance pair $[R_l,R_h]$는 비슷해야 합니다. 더 나아가서, illumination map $[L_l,L_h]$ 는 각각이 매끄럽고, 서로간에 일관성이 있어야 합니다. 이를 위해서 논문에서는 Loss ${L_{is}^{LD} := \lVert R_l - R_h\rVert_1 }$ 을 사용하여 반사율 유사도(reflectance similarity)를 정규화합니다.(${\lvert \rvert_1}$ 은 $l_1$ norm을 의미함)
Illumination의 smoothness는 ${L_{is}^{LD} := {\lVert {\nabla L_I \over max(| \nabla I_l , \epsilon |)}\rVert}_1 + {\lVert {\nabla L_h \over max(| \nabla I_h , \epsilon |)}\rVert}_1}$이고, 여기서 $\nabla$는 $\nabla x$ 와 $\nabla y$의 방향을 포함하는 1차 미분 연산을 의미합니다. 거기에 $\epsilon$은 0.001 정도의 작은 상수값을 넣어 0으로 나누어지는걸 방지하고, $\lvert \cdot \rvert$는 절대값을 의미합니다. 이 smoothness term은 입력에 대한 illumination 구조의 연관성을 측정합니다. 만약 $I$의 edge부분이라면, penalty loss $L$은 작은 값이 될 것이고, 평평한 부분이라면, 페널티가 커지게 됩니다.
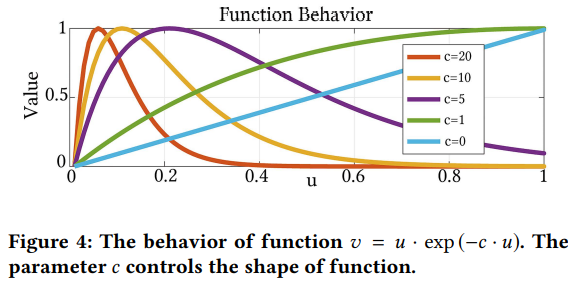
상호 일관성에 의해서, $\mathcal{L}_{mc}^{LD}:={\lVert M\circ exp(-c\cdot M) \rVert}_1$ 이라는 Loss를 채택했고 여기서 $M$은 $M := \lvert \nabla L_l \rvert+\lvert \nabla L_h \rvert$를 말합니다. Figure 4는 $u \cdot exp(-c \cdot u)$ 는 함수의 동작에 대해 보여주고 있으며, 여기서 $c$는 함수의 모양을 제어하는 파라미터입니다. Figure 4를 통해 볼 수 있듯이, penalty가 처음에는 증가하다가 $u$가 증가함에 따라 0을 향해 떨어집니다.
이러한 특성이 강한 상호 모서리?(원문 : mutual edge)가 약한 쪽에 비해 학습에서도 보존되는 일관성(mutual consistency)에 적합하다고 할 수 있습니다. 그리고 c=0으로 설정하는 것은 M을 단순한 $l^1$ loss의 형태로 만드는 것을 알 수 있었습니다. 게다가, 분리된 2개의 레이어가 reconstruction error($\mathcal{L}^{LD}_{rec}:= {\lVert {I_l - R_l \circ L_l} \rVert }_1+{\lVert {I_h - R_h \circ L_h} \rVert }_1$)에 의해 제한된 입력 이미지를 재구성해야합니다. 결과적으로 decomposition net의 총 loss는 다음과 같게 됩니다.
\[\mathcal{L}^{LD}:= \mathcal{L}^{LD}_{rec}+0.01\mathcal{L}^{LD}_{rs}+0.15\mathcal{L}^{LD}_{is}+0.2\mathcal{L}^{LD}_{mc}\]decomposition network의 레이어는 각각 reflectance와 illumination에 대응하는 가지들을 포함하고 있으며, reflectance 를 담당하는 부분은 전형적인 5-layer U-Net (conv와 sigmoid) 구조로 되어있고, illumination을 담당하는 부분은 2개의 conv+ReLU layer들과 reflectance 가지에서 넘어오는 부분과 합치는 conv와 concat 레이어로 구성(illumination으로부터 texture를 분리하기 위해서(??))되어 있습니다. 이는 최종적으로 conv+ sigmoid layer로 합쳐져 illumination을 분해하는 역할을 수행합니다.


Reflectance Restoration Net
Low-light image에서 뽑아낸 reflectance는 밝은 이미지에서 뽑아낸 것에 비해 degradation의 영향을 더 많이 받습니다. 지저분한 것에 대해서 clear reflectance가 reference의 역할을 수행할 수 있도록, restoration function을 설정하였고, 식으로 표현하면 다음과 같습니다.
\[\mathcal{L}^{RR}:={\lVert \hat{R}-R_h \rVert}_{2}^{2}-SSIM(\hat{R}, R_h)+ {\lVert \nabla \hat{R}-\nabla R_h \rVert}_{2}^{2}\]여기서 SSIM은 구조적 유사도를 측정하는 함수를 의미하고, $\hat{R}$은 복원된 reflectance에 대응되는 값이며, ${\lVert \cdot \rVert}_2$는 $l^2$ norm(=MSE)을 의미합니다. 이 세 번째 식은 texture간의 유사도를 찾는데 집중하며, 이 subnet의 구조는 이전 장에서 소개한 decomposition net과 비슷하지만, 좀 더 깊은(deeper) 구조를 갖고 있습니다. 구조에 대한 묘사는 figrue 2.의 구조 전체 그림에 나와있습니다. 앞서 degradation이 reflectance에서 복잡하게 분포하고 있고, 이는 illumination의 분포와 관련이 있다고 맗한 적이 있습니다. 그러므로, illumination 정보를 restoration net에 degraded reflectance와 함께 넣습니다. 이 방법의 효과는 figure 5.에서 확인해 볼 수 있는데 2개의 reflectance map을 다른 degradation level로 넣었을 때, BM3D의 결과는 공평하게 noise를 제거하였습니다.(자연적인 색분포를 고려하지 않고, 일괄적인 적용)
따라서 흐릿함 효과를 넣었던 흔적이 곳곳에 존재합니다. KinD의 경우, 기존의 밝기나 오염이 적었던 창문 영역은 여전히 깨끗하지만, 어두운 영역(병의 문자와 같은)의 경우 보정된 것을 볼 수 있습니다. 게다가, 색의 왜곡 또한 잘 제거되는 것을 볼 수 있습니다.
Illumination Adjestment Net
KinD 학습에 사용되는 image들에 대한 ground-truth의 밝기 레벨이 존재하지 않기 때문에, 다양한 밝기값의 조정을 위해서는 한 가지의 밝기 상태(light condition)를 다른 밝기 상태로 유연하게 조정할 수 있는 메커니즘이 필요합니다. Illumination pair의 정확한 관계를 알지 못하더라도, 대략적으로 빛의 세기의 비율(=ratio of strength) 즉, 요소별로 나눠져 있는 값의 평균 세기 $\alpha$를 계산할 수 있습니다. 이 비율($\alpha$)은 원본의 밝기 $L_s$를 target의 밝기 $L_t$로 조정하는 학습의 지표로 사용될 수 있다. 만약 낮은 레벨의 밝기를 높은 레벨의 밝기로 조정할 때, $\alpha > 1$이 되고, 나머지는 $\alpha \leq 1$이 됩니다. 테스트를 수행할 때는, $\alpha$의 값을 사용자가 원하는 값으로 설정할 수 있습니다. 네트워크는 가벼우며, 3개의 conv layer와 1개의 sigmoid layer를 갖고 있습니다. Indicator $\alpha$는 feature map으로 확대되고, network의 input으로 활용됩니다. illumination adjustment net의 loss는 다음과 같습니다.
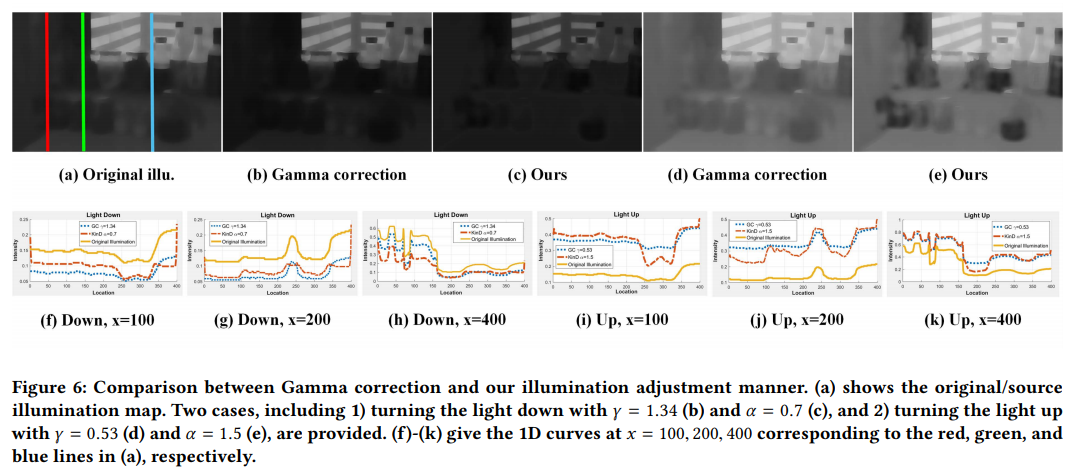
\[\mathcal{L}^{LA} := {\lVert \hat{L}-L_t \rVert}^{2}_{2} + {\lVert \lvert \nabla \hat{L} \rvert-\lvert \nabla L_t \rvert \rVert}^{2}_{2}\]$L_t$는 $L_h$나 $L_l$이 될 수 있으며, $\hat{L}$은 원본 밝기에서 target을 목표로 조정된 illumination map을 말한다. Figure 6는 학습된 조정기능(adjustment function) Ours가 gamma correction과 어떻게 다른지를 보여준다. 공정한 비교를 위해, 실험에서 $\gamma$값의 조정은 다음 식 $\gamma={\lVert log(\hat{L}) \rVert_1 \over \lVert log(L_s) \rVert_1}$ 을 통해 gamma correction 방식이 KinD의 밝기 조정기능(adjustment function)과 유사한 전체 광도에 도달할 수 있도록 하였습니다. 우리는 밝기를 올리고 내리는 일반적인 로스를 포함하지 않는 두 가지 조정방법을 고려하였습니다. Figure 6.(a)는 원본의 밝기(illumination)을 보여줍니다. (b)와 (d)는 각각 gamma correction에 의해 조정된 밝기를 보여주며, (c)와 (e)는 KinD를 통해 조정된 밝기를 보여줍니다. 차이점을 좀 더 명확하게 보여주기 위해서, 1차원으로 바꾸고 intensity curve x를 100,200,400으로 설정한 plot을 Figure 6에 같이 첨부하였습니다. Plot을 보면, KinD가 gamma correction에 비해 밝기가 내려가는 case에 대해 밝은 영역에서는 더 감소하지만 어두운 영역에서는 적거나 같은 것을 볼 수 있습니다. 밝기가 밝은 케이스에 대해서는, 반대되는 성향을 보여줍니다. 다시 말해서, KinD의 방법은 상대적으로 어두운 지역에서는 빛을 적게 증가시키는 방면, 밝은 지역에서는 더 많거나 같은 정도로 빛을 증가시킨다고 할 수 있습니다. 실제 상황에서는 학습된 방식이 더 확정적입니다. 또한 $\alpha$ 를 사용하는 방식은 사용자가 직접 밝기 정도를 조율하는 것보다 더 편리합니다. 예를 들어, $\alpha$를 2로 설정하면, 밝기값도 2배 증가합니다.
Experimental validation
Implementaion Details
이 논문의 저자들은 500장의 low/normal-light 이미지 페어가 있는 LOL dataset을 학습 데이터셋으로 사용하였고, 학습에서 450장의 이미지를 인공적으로 만들어진 이미지를 제외하고 사용하였습니다.
Performance Evaluation
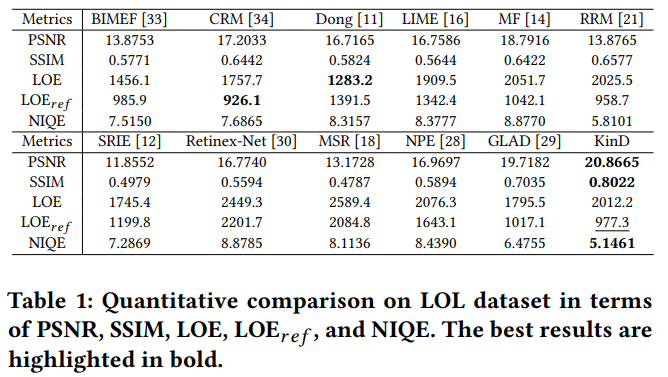
LOL dataset의 데이터를 통해 LIME, NPE, MEF등의 메소드들과 비교 를 수행하였습니다. 기준은 PSNR, SSIM, LOE,NIQE를 사용하였으며, 각각 신호대비 잡음비, 구조적 유사성 지수, Lightness Order Error, Natural Image Quality Evaluator(자연 장면 영상에서 계산된 디폴트 모델과의 비교, 점수가 더 낮을 수록 좋음)를 의미합니다. PSNR은 높을 수록, SSIM은 1에 가까울수록, LOE와 NIQE는 낮을 수록 더 품질이 좋은 영상을 나타냅니다. SOTA Method 라고 할 수 있는 BIMEF, SRIE, CRM, Dong, LIME, MF, RRM, Retinex-Net, GLAD, MSR, NPE 등 과 비교했을 때 PSNR, SSIM, NIQE에서는 더 좋은 성적을 보여주는 것을 확인할 수 있습니다.(Table 1) 다만 LOE 의 경우, 다른 방법에 비해 조금 떨어지는 것을 볼 수 있는데, reference와 비교하는 SSIM,PSNR과는 다르게 low-light 영상 input을 그대로 비교에 사용하는 LOE의 방식 때문에, KinD가 다른 방법들에 비해 강점을 못보여주는 것을 볼 수 있습니다. LOE를 개조하여 reference 영상과 비교하도록 만들어둔 $LOE_ref$의 경우에는 3등정도로 올라가는 것을 볼 수 있습니다.
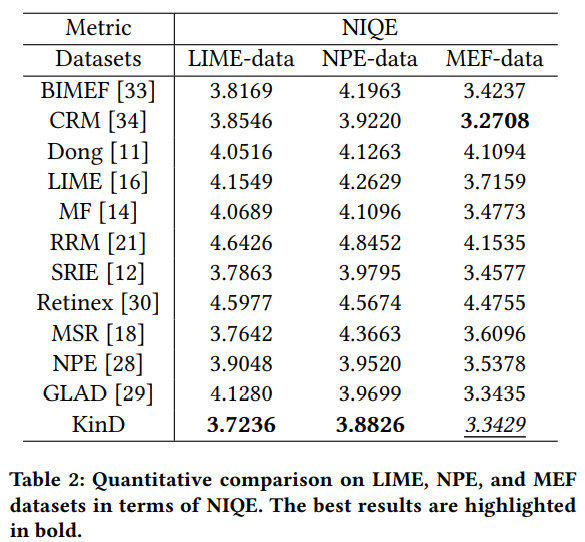
여기에, LIME, NPE, MEF의 경우, reference가 없는 방식이 때문에 LIME,NPE,MEF dataset으로 학습하고, NIQE를 통해 결과를 비교한 것이 table2입니다. KinD는 이 방식을 통해 조사한 경우에도 LIME, NPE dataset에서는 가장 좋은 결과를 보여줬고, MEF dataset에서만 CRM보다 약간 모자란 점수를 보여줬습니다.(3.34 vs 3.27)
여기에 더해 figure 7과 figure 8은 다른 방법들의 output과 KinD의 output을 비교해놓은 사진입니다. 대부분의 방법들이 입력 이미지를 밝게 할 수는 있지만, 몇몇 부분의 결함이나 빛의 조정이 만족스럽지 못하게 되는 것을 볼 수 있습니다. KinD의 경우 조명을 적절하게 조정하고, degradation들을 깨끗하게 제거하는 것을 확인할 수 있습니다.
Conclusion
KinD는 Retinex Theory에 기반한 low-light image enhancement 기법입니다. Retinex Theory에 기반하여, image를 illumination과 reflectance 2개로 나누고, 결과적으로 이 분해 과정은 원래 space를 더 작은 2개의 subspace로 만드는 과정이 됩니다. Ground-truth reflectance와 illumination 정보가 적기에, 네트워크는 대신하여 다른 빛의 세기/노출 정도의 이미지 쌍을 이용하여 학습을 수행합니다. 영상의 저하된 부분(degradation part)을 제거하기 위해서 KinD는 restoration module을 적용하였습니다. Mapping function 또한 KinD에서 학습이 되는데, 니는 gamma correction보다 실제 상황에서 더 좋은 결과를 보여주며, 더 유연하게 빛의 세기를 조정합니다.(근데 왜 감마 조정이랑 비교하는 걸까)
그리고,실험을 통해 SOTA method들에 비해 여러 dataset에서 더 좋은 모습을 보여주는 것을 확인하였고, 가벼운 네트워크라서 학습도 빠른 것을 확인할 수 있었습니다.