Deep Photo Enhancer
Deep Photo Enhancer는 2018년 발표된 논문으로, image enhnacement를 위한 Unpaired learning method를 제시하고 있습니다. 원하는 스타일로 향상된 이미지 데이터셋을 통해 이미지 향상 방법을 학습하고 input image들을 해당 스타일로 향상 시켜줍니다. DPE의 구조는 U-Net 구조에 기반한 2-way GANs을 사용합니다. Global U-Net을 GAN model의 Generator로 사용하며, WGAN을 적응형 가중치 계획(adaptive weighting scheme)으로 발전시킨 A-WGAN을 사용합니다. 마지막으로, 독립적인 batch normalization layer를 사용하여 input distributions에 더 맞게 적응하도록 GAN 학습 방법을 변경하였습니다. 이러한 구조들을 통해 DPE는 기존의 다른 네트워크들보다 더 효과적인 image enhancement를 수행할 수 있었다고 합니다.
Introduction
DPE 는 Unpaired learning을 수행하기 때문에, 사용자가 생각하는 “보기좋은” 이미지의 dataset만 준비하면 해당 dataset의 특성을 학습하여 input image를 “좋은” 이미지로 만들어줍니다. 이러한 “좋은” 이미지들은 웹사이트에서 쉽게 구할 수 있기 대문에, 기존의 enhancement 학습 방식인 image-to-image 의 translation 문제를 해결했다고 할 수 있습니다. DPE에서는 학습을 CycleGAN과 비슷한 형태인 2-way GAN을 통해 진행하는데, GAN 자체가 워낙 불안정한 학습으로 유명한 방식이다 보니, 안정화를 위한 구조가 필요하게 되었습니다. 학습의 안정화를 위해 변경한 구조들은 다음과 같습니다. 먼저 Global U-Net을 이용하여 Generator를 만듭니다. 그리고 GAN의 학습 방식은 WGAN의 방식을 사용하는데, WGAN이 사용하는 Lipschitz constraint이 penalty의 가중치 파라미터 변화에 매우 민감하므로, 이 방식을 이용하여 WGAN 학습의 수렴을 더 발전시켰습니다.(Lipschitz constraint, 이 부분은 WGAN 관련 논문을 읽어봐야 할 거 같다.) 마지막으로, 대부분의 2-way GAN 방식이 같은 generator를 사용해서 input과 output이 유사하게 mapping되도록 하는데, DPE에서는 같은 domain에서도 input들은 사실상 다른 source로 부터 온다는 것을 발견하였습니다.(한 쪽은 input data 에서, 다른 한 쪽은 generator를 통해) 이러한 불일치가 generator에 악영향을 줄 수 있으므로, DPE에서는 batch norm layer를 각 generator에 넣음으로써 generator가 input data 에 맞게 학습되도록 하였습니다.
Overview
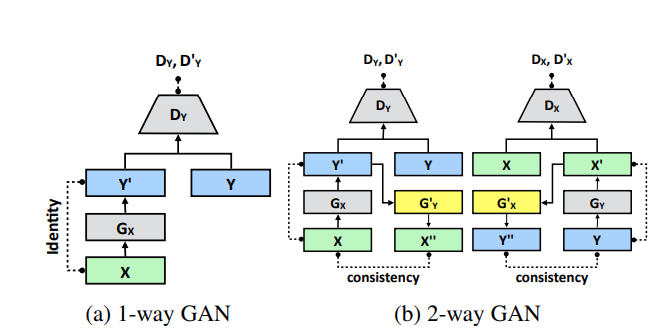
DPE의 구조는 위 fig1과 같은 모습입니다. Source domain인 \(X\)는 원본 이미지이며, target domain \(Y\)는 원하는 enhancement 특징을 가지는 image들입니다.Fig1의 (a)의 경우에는 1-way GAN의 모습을 보여줍니다.원본 이미지 \(X\)는 Generator를 통해 y의 특징을 갖는 \(Y'\) 으로 변환되고, Discriminator \(D_Y\)는 target domain y와 generator로 생성된 sample x’를 구분합니다.
Generator
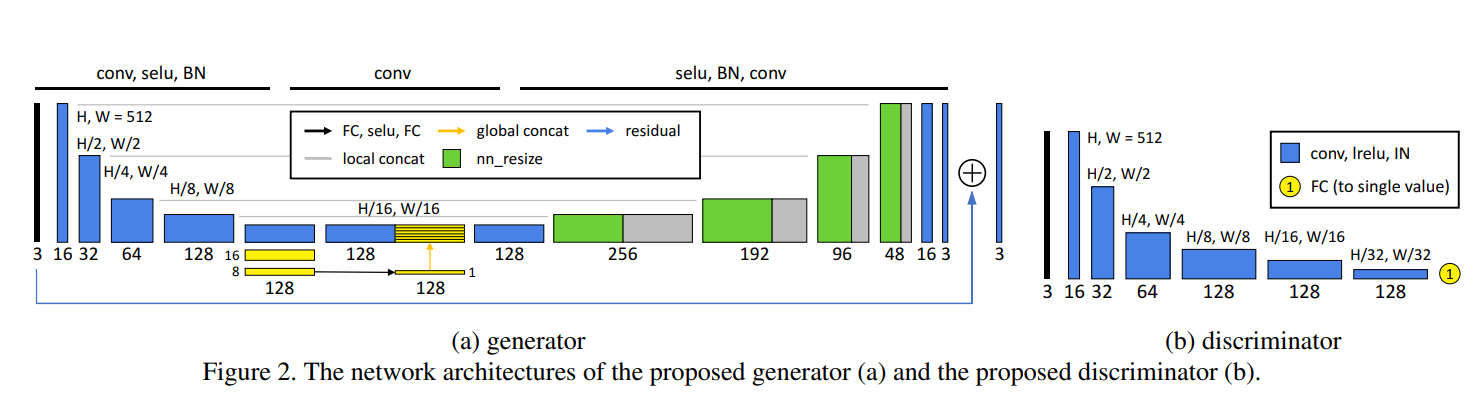
앞서 이야기한 것처럼, DPE의 Generator는 Global U-Net 구조를 사용합니다. U-Net은 생명공학 이미지의 segmentation을 위해 제안된 네트워크인데, U-Net이 다양한 연구 주제에 효과를 발휘한다는 것이 밝혀져 현재 많은 곳에서 사용되고 있습니다. 기존의 U-Net에는 Global feature를 처리하지 않기 때문에 그냥 사용하면 DPE에서 좋은 성능을 기대하기 어렵습니다. 따라서 DPE에서 사용하는 U-Net에는 Global Feature들을 뽑아낼 수 있는 레이어들을 추가하였는데, Global features를 추가하는 것이 성능에 영향을 미치는 이유는 카메라의 장면 촬영 기법과 같이 image enhancement의 큰 틀을 지정해줄 수 있기 때문입니다. 그러모르 DPE에서는 global features를 추가한 U-Net 구조를 사용하며, 그 구조를 그림으로 표현하면 fig2와 같습니다. 파란색은 convolution layer, selu, batch normalization이 포함된 conv block을 의미합니다. 첫 5개의 conv block에서는 local feature들을 뽑아냅니다.
그리고 5번째 conv block을 통과한 후 나오는 32 * 32 * 128 feature map은 global feature 처리를 위해 16 x 16 x 128, 8 x 8 x 128의 feature map으로 다시 줄인 후 FC Layer를 통해 1 x 1 x 128 크기로 만듭니다. 이렇게 만든 1 x 1 x 128의 feature map을 32 x 32 만큼 복사하여 32 x 32 x 128 의 크기로 만들어주고, low-level feature에 concat합니다. 결과적으로 32 x 32 x 256의 local feature들과 global feature들을 모두 갖는 feature map을 만들 수 있습니다. 이후 확장된 feature map을 decoding 과정을 거쳐 원래 크기로 돌린 후 residual learning의 아이디어를 접목하여 학습에 도움이 되도록 합니다. 이 과정에서 generator는 input image와 label image의 차이점에 대하여 학습하게 됩니다.
Generator의 학습에 사용한 Dataset은 Adobe5K Dataset으로, photographer C의 enhancement 방식을 채용하였습니다. Generator의 학습 실험은 supervised learning으로 진행되었으며, loss function으로는 PSNR과 SSIM을 극대화 시키기 위해 MSE를 사용하였습니다.
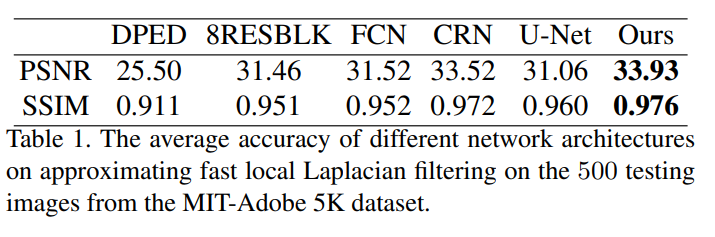
위 첨부된 2개의 Table은 DPE가 사용한 Global Feature Path를 추가한 네트워크가 다른 네트워크들에 비해 얼마나 더 좋은 성능을 보여주는지에 대해 정리한 표입니다. Table 1의 경우, Adobe5k dataset에서 500장을 random하게 뽑은 후, fast local Laplacian filtering을 통해 측정한 PSNR입니다.(Fast Local Laplacian Filters) 기존 Networks에 비해 더 좋은 성능을 보여주는것이 보입니다.
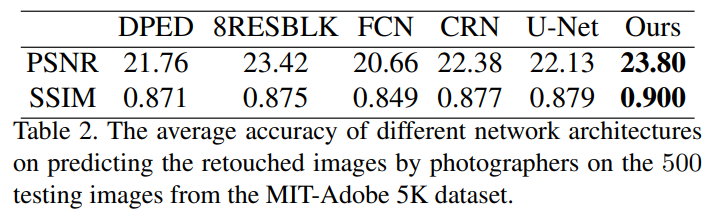
아래의 Table2의 경우에는, Adobe5k dataset 중 500장의 test image를 retouched image에 대해 predict를 돌린 결과에 대한 PSNR 측정치입니다. 이 역시 기존의 networks에 비해 높은 PSNR 및 SSIM 수치를 보여주고 있습니다.
One-way GAN
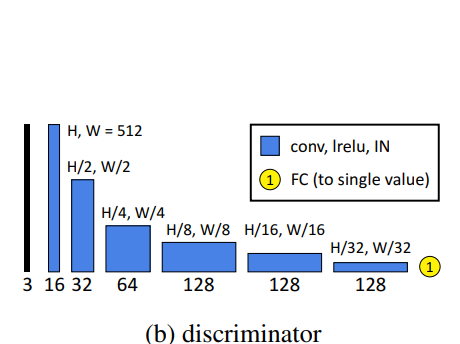
이 섹션에서는 unpaired learning을 위한 GAN architecture에 대해 설명합니다. Fig 2.(b)를 보면 discriminator의 구조를 확인할 수 있습니다. 이 discriminator와 앞서 설명한 generator를 이용하여 1-way GAN을 구축하는데, generator를 \(G_X\)로, fig 2.(b)의 discriminator를 \(D_Y\)로 설정합니다. GAN의 학습에 있어서 중요한 것은 원본과 목표 사이의 상관관계(content correlation)를 줄이는 것입니다. 따라서 GAN을 학습하기 위해서 5000장의 이미지 중 2250장을 source domain으로, 다른 2250장의 retouched image를 target domain으로 사용하였습니다. 즉, GAN의 학습을 위해서 일부분은 GAN
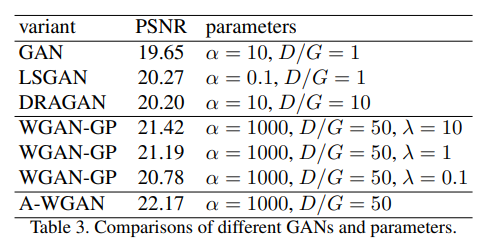
GAN을 계산하는 공식은 여러개가 있는데, 대표적으로 GAN, LSGAN, DRAGAN, WGAN-GP 등이 있습니다. DPE에 사용할 GAN 을 선택하기 위해 앞서 소개한 4가지 GAN 의 성능을 비교한 자료가 table 3입니다. table 3을 보면, WGAN-GP가 \(\alpha\)값과 \(\lambda\)값에 따라 성능이 조금씩 바뀌긴 하지만, 가장 좋은 성능을 보여주는 것을 확인할 수 있습니다. 여기서 파라미터 \(\alpha\)는 weights of identity loss를, \(\lambda\)는 weights of gradient penalty를 의미합니다. WGAN은 Lipschitz constraint(Lipchitz Constraint 참고.)을 학습에 사용하는데 다음과 같은 gradient penalty 공식을 이용하여 직접적으로 discriminator의 output gradient norm을 제한합니다.
\[\underset{\hat{y}}{\mathbb{E}}[(||\nabla_{\hat{y}}D_Y(\hat{y})||_2-1)^2]\]여기서 \(\hat{y}\)는 generator distribution과 target distribution 점 사이의 선을 따라 샘플링되며, \(\lambda\)는 original discriminator loss에 따라 가중치에 penalty를 부여합니다. \(\lambda\)값은 gradients 의 approach 1에 대한 경향을 결정합니다. 만약 \(\lambda\)값이 너무 작다면, Libschitz constraint는 확실해질 수 없고, 반대로 또 너무 커지면, penalty가 너무 커져서 모델의 수렴이 늦어질 수 있습니다. 따라서 \(\lambda\)값을 선택하는 것은 매우 중요합니다. DPE에서는 위의 공식과 다른 gradient penalty 공식을 사용했는데 그 공식은
\[\underset{\hat{y}}{\mathbb{E}}[max(0,||\nabla_{\hat{y}}D_Y(\hat{y})||_2-1)]\]입니다. 이 공식은 gradients가 1보다 작거나 은 Lipschitz를 더욱 잘 반영하고, 1보다 큰 부분에 대해서반 페널티를 부여합니다. 더욱 중요한 점은, 이 구조에서는 weight \(\lambda\)의 조정을 위해 적응형 가중치 계획(adaptive weight scheme)를 채택하였으며, 이 방법을 통해 gradient가 원하는 간격[1.001, 1.05] 내에 위치하도록 할 수 있는 적절한 가중치(weight) 값을 선택할 수 있습니다. 만약 슬라이딩 윈도우(size=50) 내에서 gradient의 평균이 이동하는 게 상한치 보다 크다면, 이는 현재 weight값 \(\lambda\)가 너무 작고 페널티가 강하지 않아서 Lipschitz constraint가 보장되지 않는다는 것을 의미합니다. 그러므로, weight를 2배로 늘림으로써 \(\lambda\)를 증가시킵니다. 반면에, 평균의 움직임이 하한치보다 작은 경우에는, \(\lambda\)값이 지나치게 커지지 않도록 절반의 값으로 줄입니다.
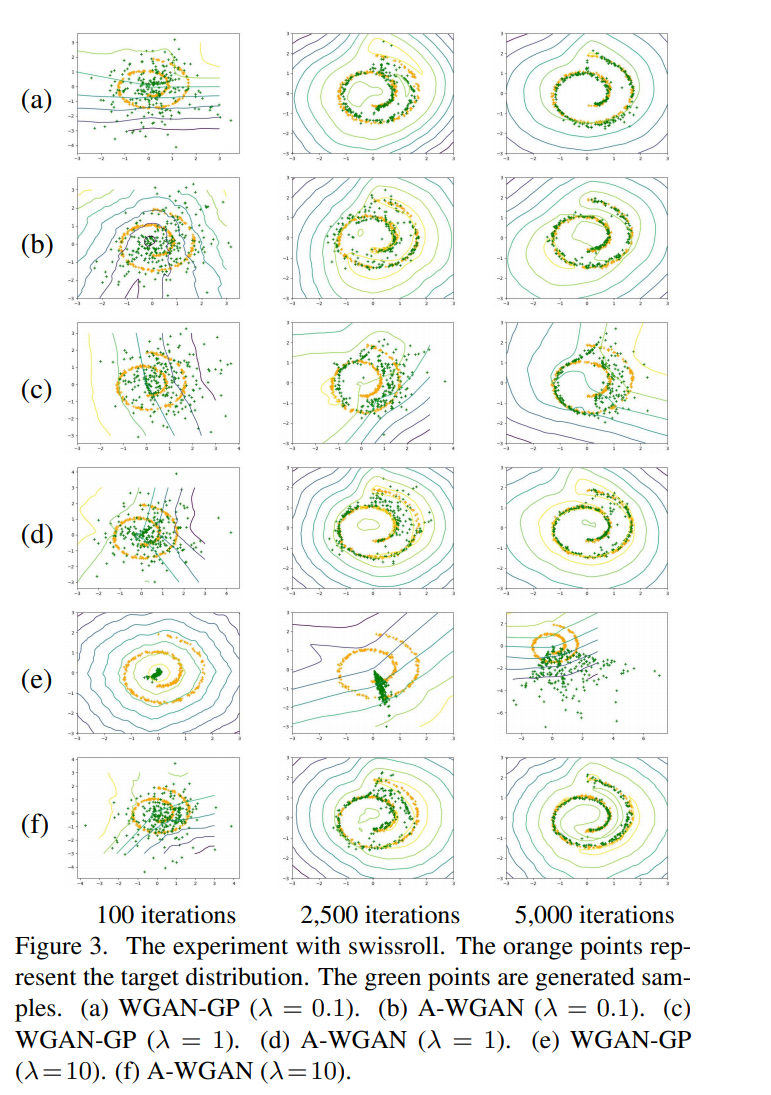
fig 3은 WGAN-GP와 제안된 A-WGAN(Adaptive WGAN)의 swissroll dataset에서 비교를 그림으로 나타낸 것입니다. 그림을 보면 A-WGAN의 경우는 초기 설정인 \(\lambda\)값에 영향을 받지 않고 수렴하는 것을 볼 수 있으며, WGAN-GP는 수렴 여부가 \(\lambda\)의 영향을 받는 것을 확인할 수 있습니다. 또한 Table 3을 보면, A-WGAN의 PSNR 성능이 WGAN-GP을 비롯한 다른 비교된 GANs에 비해 더 뛰어난 것을 확인할 수 있습니다.
Photographer들의 취향이 각각 다르고, 일관적이지 않은 주관성을 띌 수 있기 대문에, 정확한 mapping을 측정하는 것은 불가능합니다. 그나마 최선의 방법은 훈련 데이터에서 이러한 이미지들의 특성에 대한 일반적인 추세를 발견하는 것입니다. 하지만, 사람의 label을 정확하게 예측하지 못하더라도 학습된 operation들은 이미지의 품질은 향상시킬 수 있습니다. 이러한 과정은 2-way GANs에서 다룹니다.
Two-way GAN
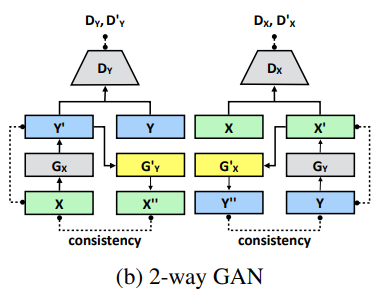
앞 Section 에서 DPE에서 사용할 A-WGAN에 대하여 설명하였습니다. 1-way GAN에 이어서, 더 좋은 결과를 얻기 위해 이번 section에서는 2-way GAN 구조로의 확장을 시도합니다. fig 1.(b)를 보면 2-way GAN에 대한 구조를 보여줍니다. Table 4.에서는 WGAN-GP와 A-WGAN을 사용했을 때 각각의 구조에서 PSNR 성능이 어느정도 나오는지 비교하여 정리하였습니다. A-WGAN과 WGAN-GP 모두 2-way GAN 방식을 채택했을 때 성능이 더 좋아지는 것을 확인할 수 있습니다.성능 자체는 A-WGAN이 더 높지만, 향상의 정도는 WGAN-GP쪽이 더 가파르게 상승하는 것을 볼 수 있습니다.
대부분의 2-way GAN들은 같은 generator 2개(\(G_X\) and \(G'_X\))를 사용합니다. Domain \(X\) to domain \(Y\)가 \(G_Y\)와 \(G'_Y\)에 비슷하게 일어나야 하기 때문입니다. 하지만 fib 1.(b)를 보시면, \(G_X\)의 input이 \(X\)의 sample에서 사용되고,, \(G'_X\)의 input은 \(X'\)의 sample에서 사용되는 것을 볼 수 있습니다. 이들은 서로 다른 분포 특성(distribution characteristics)을 가질 수 있으며, 이는 \(G_X\)와 \(G'_X\)가 input들에 더 잘 적응할 수 있도록 만들어줍니다. DPE에서 제안한 방법의 핵심 중 하나인 iBN(individual Batch Normalization) layer들이 각 Generator에 존재합니다. 이는 \(G_X\)와 \(G'_X\)가 batch normalization layers를 제외한 모든 레이어와 파라미터들을 공유한다는 것입니다. 각 generator들은 독자적인 batch normalization layer를 가지며, 이는 각각의 input들의 특성에 맞춰 적응합니다. Table4.는 individual batch layer를 도입했을 때 어느 정도의 성능 향상을 볼 수 있는지 에 대해 표로 나타내고 있습니다. iBN을 도입한 결과, WGAN-GP 와 A-WGAN 모두 성능의 향상이 이루어진 것을 볼 수 있습니다.


fig4와 fig5를 보면, iBN을 사용하는 2-way GAN에 비해 iBN을 사용하지 않은 2-way GAN은 특징 분포를 포착하는데 실패한 모습을 볼 수 있습니다.
종합하자면, DPE에서 제안하는 목표에는 몇개의 loss들을 포함합니다. 가장 먼저 특성 매핑 로스 (identity mapping loss) \(I\)는 변화된 이미지 \(y\)와 input image \(x\)간의 유사도를 측정합니다. 2-way GAN에서는 \(y\)를 \(x'\)로 mapping하는 경우도 있기 때문입니다.
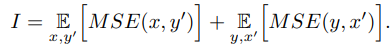
두번째 loss는 cycle consistency loss C이며, 다음과 같이 정의됩니다.
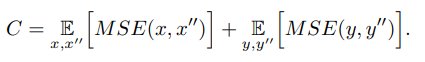
Discriminator \(A_D\) 와 generator \(A_G\)를 위한 advversarial losses는 다음과 같이 정의됩니다.
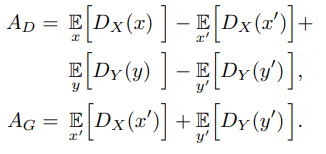
Discriminaotr 를 학습하기 위해서는, gradient penalty \(P\)를 정의할 필요가 있는데, 이는 다음과 같습니다.
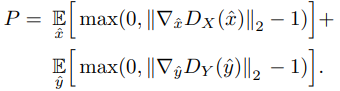
Wasserstein distance를 위한 1-Lipschitz functions을 보증할 필요가 있기 때문에, discriminator 는 다음 optimiaztion에 의해 얻어집니다.
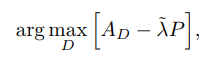
가중치 \(lambda\)가 A-WGAN을 통해 적응적으로 조정됩니다. Generator는 다음 공식을 통해 얻어집니다.
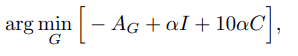
adversarial loss와 identity/consistency losses 사이의 \(\alpha\) 가중치를 의미합니다. 최종적으로, 우리는 결과로 generator \(G_X\)를 얻게 되고, 이를 사진을 향상시키는 도구 \(\Phi\)로 사용할 수 있습니다.
Results
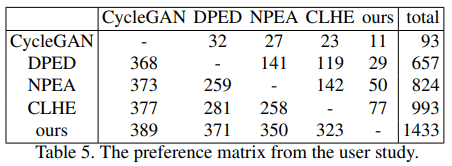
Results에서는 DPE를 통해 나온 이미지가 어떻게 학습되었는지, 그리고 20명의 참가자를 대상으로 CycleGAN, DPED, NPEA, CLHE, 그리고 DPE를 통해 enhanccement 된 이미지 20장을 보여주고 어떤 것을 가장 선호하는지 조사하여 가장 높은 선호도를 보였다는 것을 말하고 있습니다. table 5.는 그 결과를 보여줍니다. CLHE와의 선호도 비교에서 81% 가까이가 DPE를 선호한다는 것을 보여줍니다.
이외에도 DPE가 제시하는 새로운 것들로 3가지를 꼽았는데 A-WGAN, global U-Net, 그리고 iBN입니다. 셋 모두 위에서 설명한대로, 기존의 방식들보다 더 좋은 성능을 보여주었습니다.